




Pandas vs Excel - Which is Better for Data Analysis?

We all know an Excel spreadsheet when we are looking at it. Excel is widely famous for its simplicity, the “easy to understand” visualizations of datasets, and all you can do on Data Analysis with basic knowledge. But, is it the best?
Python allows us to work with Pandas – another tool for data analysts to master that offers a wider range of benefits. With all of what Excel can do, Pandas would reach beyond that and, in more advanced scenarios, it will be even easier to do. But when you read that you need some coding knowledge to use it, that first learning curve already starts pretty high for some people.
Is it like that? We will see at both Microsoft Excel and Python Pandas, which one is the best and how much it requires for anyone to get the best of each program.
Table of Contents
What is Excel?

Microsoft Excel is a software that provides data visualization and data analysis through the use of spreadsheets where you can organize, store and track data sets with formulas and functions.
It is commonly used by many data analysts, accountants, and any other kind of professional. Microsoft Excel users will identify trends and organize and sort data into categories.
This Microsoft program is a key component for their MS Office package, and it helped a lot of businesses with their job.
What is Pandas?

Python Pandas is a machine learning software library extension that works with data stored in Python to manipulate and analyze it.
The first advantage over Excel is that Pandas is Open Source, meaning that you can download it for free, whereas in Excel, you need to buy a license to use it. Pandas Python libraries are used by data scientists and analysts for many kinds of tasks.
It’s a powerful tool, much faster, and can manage large datasets with ease. It will require some basic learning of Python and programming language.
If you already know something about it, you should know that it is built on NumPy (Numerical Python) and allows you to use Pandas with other available libraries such as Scikit-Learn, Flask, Django, or Plotly.
Main Advantages of Pandas
Excel got its simplicity and readability. But Pandas is just a few steps away from them, and in more complicated scenarios, it is way over what Excel can do, sometimes being even easier to do with Pandas. Let’s dive into each of the advantages that Pandas offer.
HTML, SQL, CSV; Pandas Can Read It for You

You can import data sets to Pandas in up to 15 different formats and switch between them. You can receive SQL files and export them back in HTML format.
For Excel, you have to expend more time on converting, for example, a SQL format to CSV format, or even use a third-party program before you can open it as an Excel document. And even then it’s not secure as the formatting could get ruined and kill data as a result of the process.
Pandas provides a uniform way to deal with them in the same manner.
Automation, Speed, and Capacity

Most of the tasks you can do with Pandas are easy to automate, reducing the amount of tedious and repetitive tasks you need to perform daily. This automating process includes repairing data holes and eliminating duplicates.
Pandas is also faster than Excel, and you will notice when we need to deal with large data sets. Excel can’t exceed 10,000 rows before it starts to slow down considerably. A single spreadsheet will reach over 1 million rows where, at that point, any kind of calculations would take forever to complete, or the software will just crash.
Pandas operates on the back of Python and is only limited to your computer power and the computer memory where it is running.
For that reason, it has no limitations on data points that you can have in a dataset (called DataFrame). You can compute millions of data points instantly with Pandas and, since it is an open-source software, there are lots of Python libraries that can streamline the length of time that your calculations take.
Fixing Errors and Data Cleaning

In Pandas, it is very easy to understand what is happening on each task that’s running, making it easy to find and fix errors.
As it’s Machine Learning software, Pandas will read data and categorize it automatically at a fast pace.
One of the big wins for Excel is its graphs and charts. They are easy to use and understand. But Pandas doesn’t get behind and even theirs are more customizable than Excel.
Pandas vs Excel - A comparison Step by Step
Going forward, we will take some examples of how some work is done in Excel and compare the same task with Pandas.
Importing Data

In Excel, all their data is presented on an Excel spreadsheet. First of all, it should be in a compatible format. It will contain columns, rows, and cells of data.
In Pandas, we need to use the appropriate method to read data. We will be greeted with “Import pandas as pd.” The first thing we need to do is to establish the DataFrame and import our file. Let’s say that we have a CSV file. We will write the name of the DataFrame = pd.read_csv (“file name.csv”). With the “pd” syntax, the software will read our document as “Pandas” now and we can continue working on our Pandas DataFrame.
If it is an Excel file, we just write pd.read_excel. Once our DataFrame is established, we can look at it using the Head() method, displaying the number of data that you want.
Differences on Visualization

The column names in Pandas are taken from the data, whereas in Excel they have to be previously labeled with letters.
For all missing data, Excel will leave it in blank spaces. As for Pandas, it has a placeholder “NaN” for missing values.
The numeric values in Pandas would have a decimal point added to each rounded value. That’s because Pandas stores null (NaN) numeric data as float. In the end, this doesn’t have any effect on your results, and it’s just visualization.
Selecting Data

In Excel, this is pretty straightforward. Just click any of the rows that you want to highlight or use keyboard shortcuts.
In Pandas, it is easy too. Just insert the name next to the DataFrame in brackets and it will display the row that you want to look apart. And if you want to look at multiple ones, just add the name next to the previous one separated with a coma.
Sorting Data

In Excel, it is pretty easy. Select all the data that you wanna sort. Then click on the “Sort and Filter” button and a new window will pop up. There you can select which values you want to sort and in which order.
In Pandas, you need to use the sort_values() method. In brackets, we introduce the value from which we want to sort our data. By default, it will be in ascending order.
Filtering Data

In Excel, we need to select the first cell in the “Title” column. Then we go to the “Data” tab and click “Filter.” It will appear arrows next to the column names. We select from which column we want to filter, click the arrow, and a new menu will drop down. There we can select the value or values that we want to filter.
As a result, it will appear only the items that share the same value that we selected.
In Pandas, It is just one more step on the line of code as it is in “selecting” that we need to do.
We need to specify that we want to use the same DataFrame as it would be DataFrame[DataFrame[“Column Name”] = Value], where “Column Name” would be from which item we want to filter, followed by the values on the code string.
Summing and Susbstracting Data Points

In Excel, we need to create a column that will hold the results. Enter the column name on the first cell. Then we click the one below and enter the formula. To subtract two data columns, you can use the “=cell1-cell2” formula.
If you want the result of summing up various values in the same row, you can use the “=SUM(first cell:last cell).
Then, drag the formula on all that you need, or you can propagate on all cells below by double clicking the last one.
In Pandas, you can do it with simple coding. Between columns, we need to specify the name of the new column next to our dataset, using the sub() method, and insert its name next to it, followed by which column we want to calculate.
If we need an operation between rows, we will start selecting each column by writing its names on the code string and naming it as it will be on the new column. Next, we will use the sum() method and specify axis=1, as we want to do operations between the data in the same row and not in the same column.
In Pandas, the formulas we used aren’t stored, and the resulting values are added to our data set. If we want to adjust, we need to write a new code to it.
Joining and Merging Datasets

In Excel, if we have two sheets and want to merge them using some columns that have data in common, we use the VLOOKUP() formula.
As in the previous example, we name a column that will have the data merged. We click on its first empty cell and insert the formula “=VLOOKUP.” Then we introduce the first data to merge. Next, we select all the cells which we want to merge. Then the location of the LOOKUP formula. Then, the number of columns we want to merge, followed by “FALSE” to find the exact match.
In Pandas, we need to import data from the second file, just like in the first example. After that, we will use the pandas.merge() function on the second line.
We specify the first data set for the merge; then the second data set to merge; how we want to merge our data, with the name of the new column; and last the column they have in common: DataFrame = pd.merge(FirstDataFrameName, SecondDataFrameName, how=”New Column Name”, on=”Column Name in Common”.
Pivot Tables

One of the most successful features in Excel is the Pivot Tables. It facilitates data analysis using aggregation. We will need to go to the “Insert” tab and then click “Pivot Table.” There we choose the data we want to analyze and that we want to be placed in a new worksheet.
On the right side, we will have a panel with our columns’ names. Select what you want to look at and it will automatically sum up their data points.
If you want to change the operation (subtraction, get a percentage, etc.), you can go to the sum on the right panel, click it, and select the option “Value Field Settings,” where you can change it.
To create a Pivot Table in Pandas, we use the pivot_table function. This will require a bit longer line of code, finishing with the “mean” function. This can be summed up as table = pd.pivot_table(data=Data Frame, index=”Column 1”, values=”Column 2”, aggfunc=”mean”).
A Bonus from Pandas
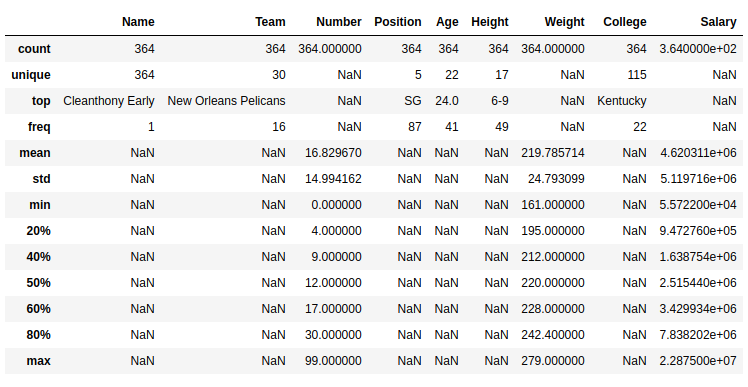
We will give you an example of two useful Pandas Methods to do a close up on what is capable.
We can use the describe() function for descriptive statistics on all variables in any of our datasets. It can analyze data both numeric and non-numeric.
For numeric, it result’s index will be: count (it describes the number of data points inside the column); mean (its mean value); std (standard deviation); min (minimum value); 25%; 50%; 75%; and max (the biggest value).
For non-numeric, their result’s index would be: count; unique (the number of unique values); top (most common value); and freq (common value’s frequency).

The other Pandas method is the info() function. You can use it to find out information about any of our datasets. This will include the data types that we have in each column, how many data points there are, and how much memory our dataset takes up.
So, Should I Go for Pandas or Still Use Excel?

One can be a fine Excel user with a relatively low skill set. It will perform fine on the basics and even pretty well on advanced statistics. It’s good at creating graphs for data analysis and data reports. It is easy to modify and flexible in its procedure.
What’s more, Excel is famous worldwide, so even if you don’t know how to perform a specific task, you will always find plenty of guides over the web that explain it like you were a child. If you think Excel would better fit your goals, you can acquire the whole Office package with RoyalCDKeys for peanuts. Grab yourself an MS Office 2021 CD key now!
With Python and Pandas, you can work on many data formats. You won’t have an issue importing the most used data format as Pandas library supports around 15 different data formats. It doesn’t have any speed limitation when dealing with millions of variables on its database. It can save time and achieve the same or better results with a simple line of code on more advanced tasks. It’s free and, overall, the best tool for data science.
Of course, the big negative comes from learning Pandas. It will require, at least, an essential skill set in programming language to achieve good results on data analysis. But if you will work as a data scientist, without a doubt, Pandas is the best answer. Its benefits on analysis overwhelm this first wall of learning.



